
The Story
It’s been about a year and a half since I started learning and using Python. While the learning ceiling is still pretty high, I’ve gotten a solid foundation on the programming language and dangerous enough to how I want to accomplish something. When you add on the desire to pick up data engineering skills since the summer of 2023, this bookstore ETL project comes to life.
Upskilling in a self-paced manner requires patience and discipline, but incorporating some personal interests has never failed to drive a concept home for me. In this project, I’m simulating a bookstore receiving book shipment orders and storing the records of books into a relational database. I created a few CSV files containing the titles of several kinds of books, but I used the thriller book list in light of my favorite fiction genre.
Objective
Create an ETL pipeline that extracts book shipment orders (CSV files) from an file folder location, performs a series of transformations on the order data, and loads the cleaned data into a local PostgreSQL database. The purpose of this pipeline is to:
1) keep an organized record of ordered books for the store’s inventory,
2) eliminate manual intervention of the book order records, and
3) provide downstream users with clean data for high-quality analysis.
Tools Used

Python – programming language that drives the ETL pipeline 
Spyder – Python IDE to write the pipeline script 
PostgreSQL – relational database to store the book records 
DBeaver – SQL IDE used to interact with the database 
Perplexity – AI chatbot to create the datasets 
Excel – spreadsheet software used to create the workflow diagram
Process
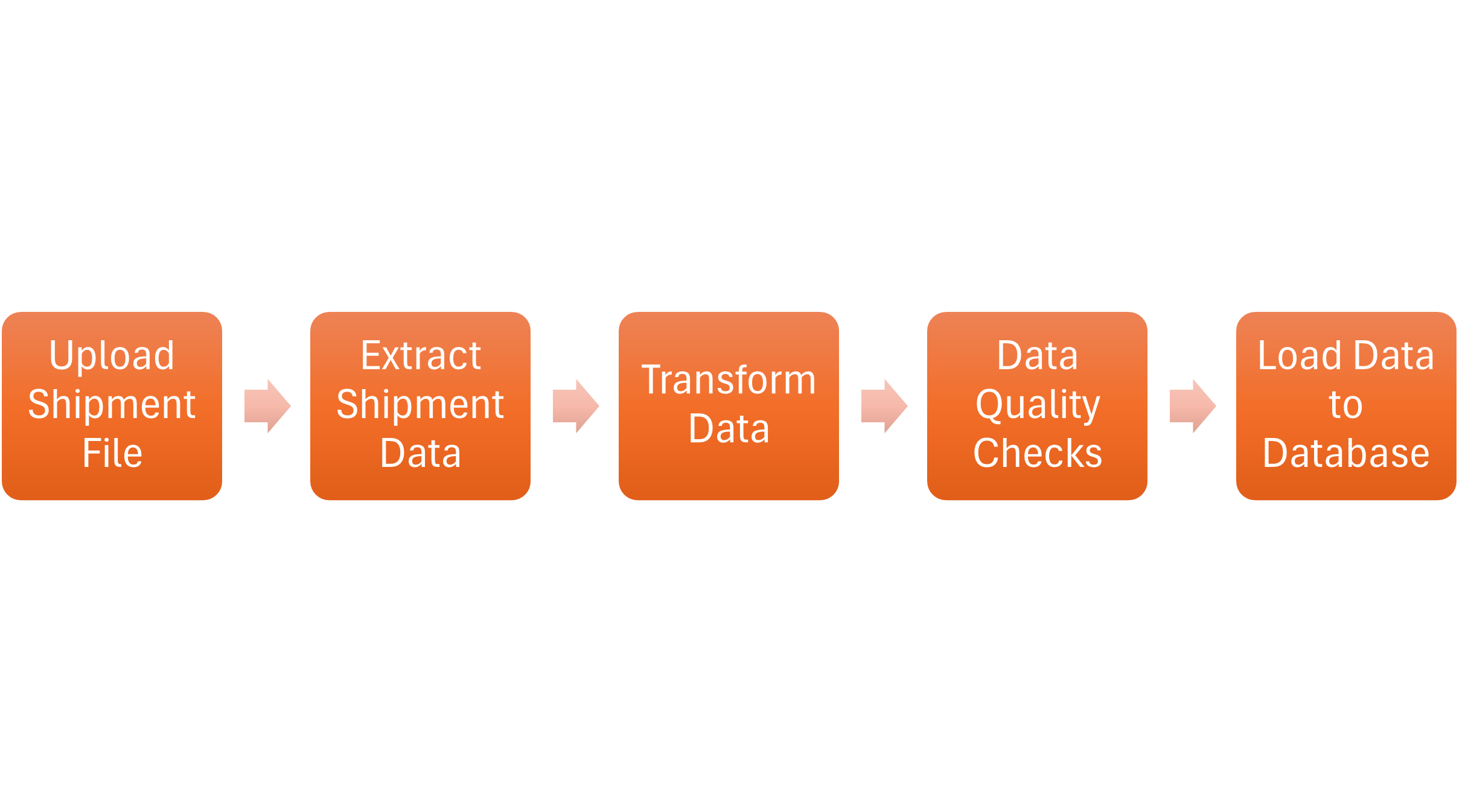
1) Designing the Pipeline. I decided on making a simple ETL pipeline design that is manageable for a small business and takes a solid database structure into consideration. Given the batch nature and amount of data expected to flow into the bookstore’s database, keeping everything local was the suitable option. Below is a diagram of the pipeline:

2) Designing the Database Table. This step required me to think about the data from two perspectives: the stakeholder and the data engineer. The stakeholder would think of the data in terms of the outcome and what they would want to measure. They would probably ask questions like:
- How often do we need to place orders for low inventory?
- What kinds of books are we selling the fastest?
- What kinds of books are we selling the fastest?
The data engineer would think of the data in terms of the most efficient way to reach the outcomes. Once they understand what the stakeholders want, their questions may include:
- What data types should be considered for each data point?
- How much storage does our database have?
- What database design can account for future expansion as the business grows?
While there are generally several tables in a database to optimize storage and performance instead of a single table, I still selected the order file fields based on these two perspectives. Here’s the resulting SQL code used to create the table:


3) Creating the Datasets. To create safe and sufficient data to use for this project, I utilized Perplexity to generate the datasets with the following prompt:
In the context of the ETL pipeline above, I would like to emulate a bookstore receiving shipments. The datasets would represent shipment orders. I would like three csv files with following fields: order_id, order_date, shipment_date, book_id, title, last_name, first_name, genre, publication, price, and quantity.
Publication refers to the year it was published and the first and last names are in reference to the author. The order date should be between 1/1/2025 and today while the shipment date should be any date within five days of the order date. The quantity should be any number between 5 and 15. All of the book titles should be unique. I would like all dates stored as text in “mm-dd-yyyy” format, the quantity and price data to have one decimal place, and the first and last names to be formatted in a variety of upper, lower, and proper cases.
The first file should have 45 thriller novels, the second file should have a variety of 63 personal development or professional development books, and the third file should have 58 books related to data analysis, data science, or data engineering.
4) Writing the Pipeline Script. I utilized the following Python libraries to construct the Python code:
- Pandas – data manipulation and data quality checks
- NumPy – condition-based data quality check
- DateTime – formatting date and time strings
- Time – time recording of the code execution
- SQLAlchemy – database interaction
- Psycopg2 – PostgreSQL database engine interaction
The code was then split into five sections:
EXTRACT
After the shipment order file has been “uploaded” to its drop location, the script will extract the data and put it into a DataFrame.

TRANSFORM
There are three sets of transformations that are performed within one functions:
1) Date Transformation – The date strings are changed into a MM-DD-YYYY datetime format. This is applied to the Order Date and Shipment Date columns.
2) Case Transformation. The First and Last Name columns are standardized to a proper case.
3) Number Transformations. To ensure proper totals can be calculated from the numerical data, the Quantity column is converted to an integer data type and the Price column is converted to a numeric data type.

DATA QUALITY CHECKS
Before the data is loaded, the script checked the quality of the data to ensure the following:
1) All the Order IDs are unique and not null.
2) All the Books IDs are unique and not null.
3) The Order Date is older than the Shipment Date.
4) There are no strings within the Quantity and Price columns.

LOAD
The cleaned data is loaded into two locations. One is the PostgreSQL database and the other is a file folder in the form of a CSV file. The goal is to have a copy of the processed data stored as a backup to the database.


DOCUMENTATION
To document the script run, a log file is created to summarize the records that were inserted into the database table.

Reflection
Loyalty to Your First IDEs. As exciting as it can be to get your hands on new technology, this can add more time to your project. Furthermore, the ceiling to learn all the helpful feature of a tools are usually pretty high. Spyder and DBeaver were the platforms I learned Python and SQL on and found that sticking with those eliminates the burden of simultaneous learning of data concepts, coding, technology, etc.
The Power of Kolb’s Experiential Learning Theory. Having the experience of learning the theory before practice and vice versa, the latter has a longer-lasting effect of skill retention for me. This project served as the fourth stage of Kolb’s Experiential Learning Theory where I got to experiment with concepts I’ve learned from previous experiences (active experimentation). This followed concrete experience (learning on the job), reflective observation (thinking about that experience), and abstract conceptualization (research and drawing conclusions from the reflection).
Functional First, Polished Later. Earlier in my career, I found it very easy to get lost in the details by adding bells and whistles before a task is complete, extending the time of the task altogether. The end product of the pipeline script was not how it looked in the first completed draft, but the result of walking through the code a few times AFTER I got it to complete the task.
Future Enhancements
Adding an orchestration tool. In a future iteration, I want to add an orchestration tool to the pipeline for further automation.
Code for messier data. I want to develop messier data that will, in turn, require me to add more logic to handle more complex data formats and anomalies.
Add a BI tool for a presentation layer. Once I can get more data in the database, the next logical step is to connect it to a dashboard to visualize the book inventory.
Full ETL Script
To see the full Python and SQL codes for this project, visit my Github page here.

